spotify_all <- read_csv('https://bcdanl.github.io/data/spotify_all.csv')Let’s analyze the ‘spotify’ data:
The data.frame spotify_all includes information about Spotify users’ playlists.
- The unit of observation in
spotify_allis a track in a music playlist.
Variable Description
pid: playlist ID; unique ID for playlistplaylist_name: a name of playlistpos: a position of the track within a playlist (starting from 0)artist_name: name of the track’s primary artisttrack_name: name of the trackduration_ms: duration of the track in millisecondsalbum_name: name of the track’s album
Q1a
- Find the ten most popular song.
- A value of a song is defined as a combination of a
artist_namevalue and atrack_namevalue. - Who are artists for those ten most popular song?
- A value of a song is defined as a combination of a
Answer:
popular_songs <- spotify_all |>
group_by(artist_name, track_name) |>
summarize(Count = n()) |>
arrange(desc(Count))
top_ten_songs <- popular_songs |>
head(n = 10)
top_ten_songs_artists <- top_ten_songs$artist_nameQ1b
- Find the five most popular artist in terms of the number of occurrences in the data.frame,
spotify_all. - What is the most popular song for each of the five most popular artist?
Answer:
popular_artists <- spotify_all |>
group_by(artist_name) |>
summarize(Count = n()) |>
arrange(desc(Count))
top_five_artists <- popular_artists |>
head(n = 5)
top_song_by_artist <- popular_songs |>
filter(artist_name %in% top_five_artists$artist_name) |>
group_by(artist_name) |>
slice_head(n = 1)Q1c
- Create a data.frame named
drake_one_dancethat includes all playlists featuring the song wheretrack_nameequals “One Dance” andartist_nameequals “Drake”.- Ensure that the data.frame
drake_one_dancedoes not contain any playlists where the song “One Dance” by Drake is absent.
- Ensure that the data.frame
- What is the song with the highest frequency of appearances after Drake’s “One Dance” in the newly created data.frame,
drake_one_dance?
Answer:
drake_one_dance_playlists <- spotify_all |>
filter(track_name == "One Dance" & artist_name == "Drake") |>
select(pid)
drake_one_dance <- spotify_all |>
filter(pid %in% drake_one_dance_playlists$pid)
check_drake_one_dance <- drake_one_dance %>%
group_by(pid) %>%
filter(all(c("One Dance" %in% track_name, "Drake" %in% artist_name))) %>%
ungroup()popular_song_after_one_dance <- drake_one_dance |>
group_by(track_name) |>
summarize(Appearances = n()) |>
arrange(desc(Appearances)) |>
filter(track_name != "One Dance") |>
slice_head(n = 1)Q1d
Provide both (1) ggplot code and (2) a couple of sentences to describe the relationship between pos and the ten most popular artists.
Answer:
top_ten_artist_names <- popular_artists |>
head(n = 10)
top_ten_artists <- spotify_all |>
filter(artist_name %in% top_ten_artist_names$artist_name)
top_ten_artists <- left_join(top_ten_artists, top_ten_artist_names, by = "artist_name")
ggplot(top_ten_artists,
aes(x = pos))+
geom_bar(position = "stack") +
facet_wrap(artist_name ~ .)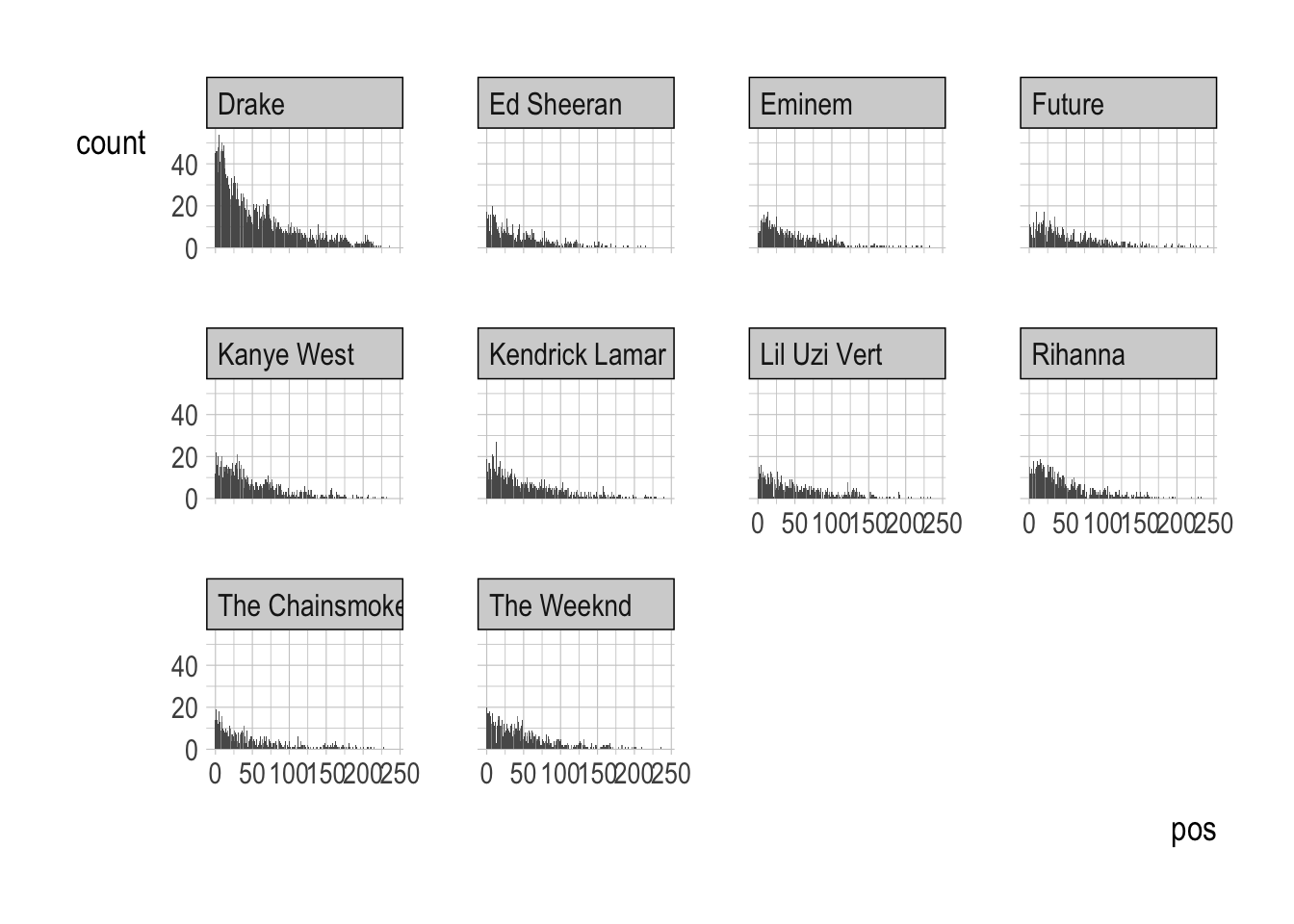
# The top ten artists all have a similar relationship with pos. They all have a higher frequency of when pos is at 0 and close to 0 and decrease in frequency as pos increases. Since these are the top ten artists, it makes sense that their songs would be at the beginning of playlists more often than at the end. Q1e
Create the data.frame with pid-artist level of observations with the following four variables:
pid: playlist idplaylist_name: name of playlistartist: name of the track’s primary artist, which appears only once within a playlistn_artist: number of occurrences of artist within a playlist
Answer:
playlist_artist_count <- spotify_all |>
group_by(pid, artist_name) |>
summarize(n_artist = n()) |>
ungroup()
playlist_artist_level <- spotify_all %>%
select(pid, playlist_name, artist_name) %>%
distinct() %>%
left_join(playlist_artist_count, by = c("pid", "artist_name"))
playlist_artist_level <- rename(playlist_artist_level, artist = artist_name)